One of my motivations for getting into computer vision was to create 3D models of my cats. I’m not alone in my fascination with these regal creatures, they have captivated some of the best of minds. So, in this post I’m going to share some fun ideas in computer vision through the medium of cats. Naturally, Eve and Peek-a-boo, my feline friends, are going to feature in the post.
Aspects of Perception
The earliest known research paper in computer vision that features a cat dates back to 1954 1. It is a formative paper in psychology that deals with human perception. The author, Fred Attneave, demonstrated through his work that most of the information received by any higher organism like us is actually redundant. This means we only need a fraction of the stimulus we receive to understand the world around us.
He illustrated this fact using, you guessed it, a sleeping cat.

He picked just those points in the image of a sleeping cat at which the direction of its contour changes rapidly, in other words the curviest points of the picture.

He then connected them with appropriate straight lines to demonstrate that the cat can be represented with great economy, and fairly striking fidelity with a very low amount of information (there are only 38 points in this picture).

This was such an interesting result that I had to verify Attneave’s claims for myself. Here are the images of my fur babies Peekaboo and Eve for reference.


I used the laplacian operator as a proxy for curvature and then thresholded the result to the top 1% of the curviest pixels.


Aspects of Purr-ception: Pixels with curvature in the top 1%
Even though I haven’t connected the points with straight line edges, we can clearly see outline of the furry fiends. With just 1% of the information, we can deduce their identity, even their posture (and maybe even their nefarious intentions).
Attneave essentially demonstrated that sketches pack a punch in terms of information. While we’re on the subject of sketches, I want to show you this cute paper from Google Brain, the research division of Google AI.
Sketch-RNN
Sketch-RNN2 is a recurrent neural network that is able to construct stroke-based drawings of common objects.
In the animation you see, I just drew the black circle and sketch-rnn is doing the rest of the work. I was mesmerized by the drawings and I let sketch-rnn run for way longer than I initially intended to. I’m sure you’ll do too!

Instead of viewing the image as a grid of pixels like a CNN does, sketch-RNN looks at sketches as a sequence of strokes and based on its training data, Sketch-RNN predicts how my initial strokes, in this case a circle, will evolve.
Taking this one step further, can we convert our AI-generated sketches into an RGB picture? Yes we can!
Sketch to Photograph by Pix2Pix
Pix2Pix3 is a generative adversarial network, or a GAN from UC Berkeley.
A GAN consists of two neural networks, one that is trained to distinguish between real and fake and the other that is trained to fool the first. This allows a GAN to produce new images that are very “real” in a sense. GANs can be applied to a variety of tasks and have become really popular.
In this variant of Pix2Pix, any sketch is converted to a cat-like photograph. I had an inordinate amount of fun trying out my sketching skills and here you can see some of my original work. The first three are mine and the last sketch comes preloaded with the software. I added it because I wanted to show how realistic the results can get. Try it out!
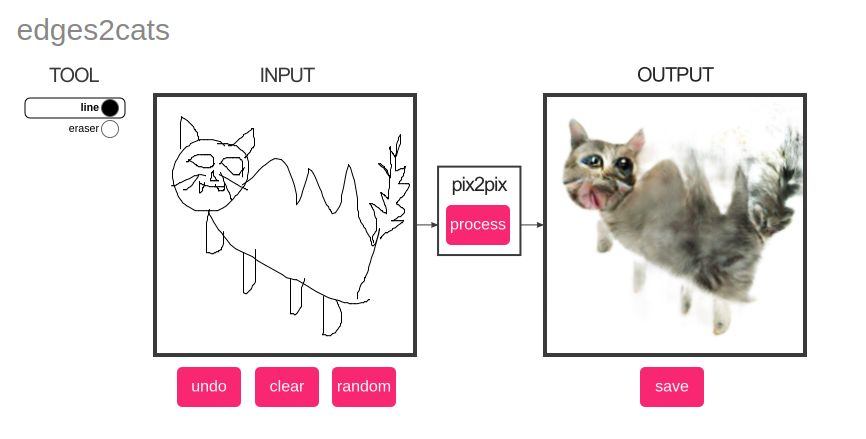
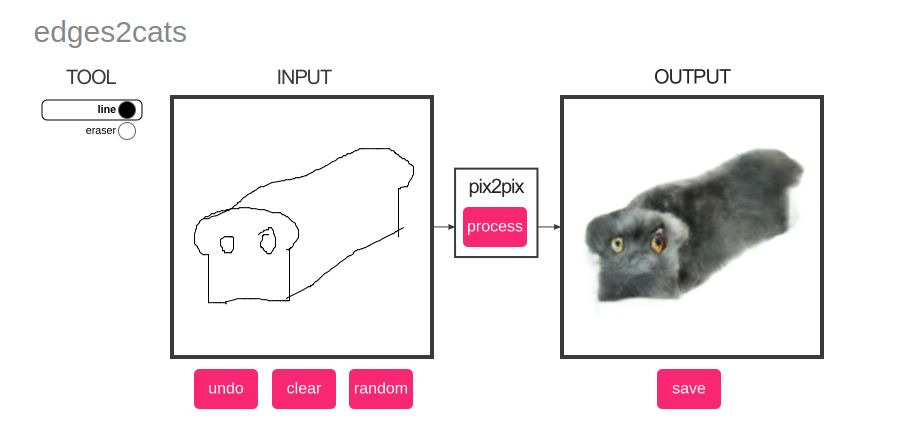
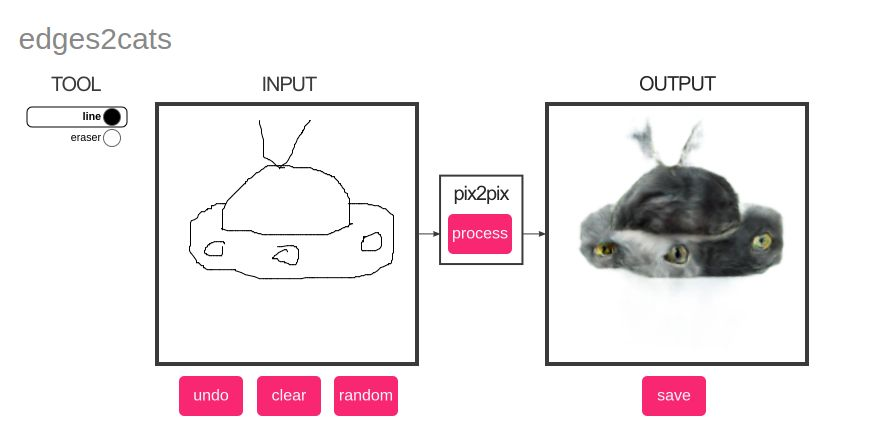
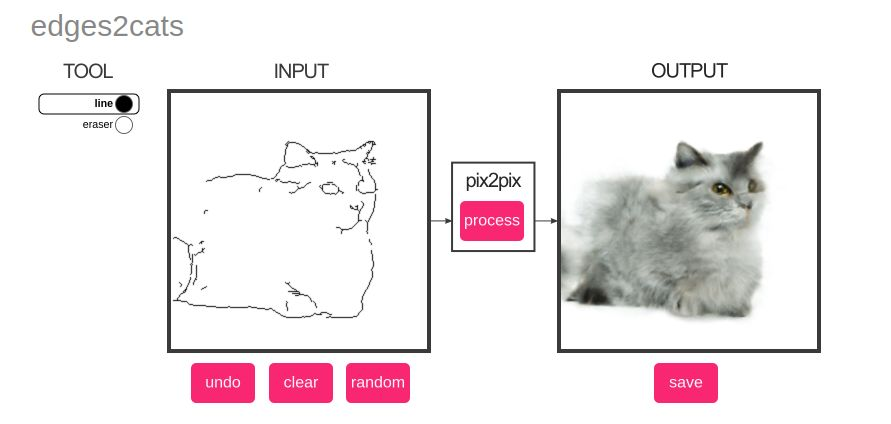
Photograph to 3D Model
The culmination of this journey would be if we could get a 3D model from a 2D photograph. So, here we are, from the University of Oxford, the winner of the best paper award CVPR 20204.


This uses a much different technique than CNNs, RNNs or GANs. It’s an unsupervised method called an autoencoder where no labelled data is provided and the network learns a representation of the provided data on its own.
Here it has learned a representation of a cat face in terms of shape, reflectance, illumination and viewpoint and it uses this information to reconstruct a 3D model of the face of the cat. The main contribution of this paper was to use the partially symmetric nature of objects like faces as an additional piece of constraint for the neural network. Take it for a spin!
Wrapping Up
The winner of best paper award CVPR this year 5 is also an unsupervised method to generate realistic 3D data. In my opinion, research is moving away from the supervised into the unsupervised domain where you either don’t need labelled data or you want to generate it to train a network.

References
-
Attneave, Fred. Some informational aspects of visual perception. Psychological review 61.3 (1954). ↩︎
-
Ha, David, and Douglas Eck. A Neural Representation of Sketch Drawings. arXiv preprint arXiv:1704.03477 (2017). ↩︎
-
Isola, Phillip, et al. Image-to-image translation with conditional adversarial networks. Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. ↩︎
-
Wu, Shangzhe, Christian Rupprecht, and Andrea Vedaldi. Unsupervised learning of probably symmetric deformable 3d objects from images in the wild. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020. ↩︎
-
Niemeyer, Michael, and Andreas Geiger. Giraffe: Representing scenes as compositional generative neural feature fields. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021. ↩︎